容器网络
Network Namespace包含哪些资源?
容器所能看到的网络栈被Network Namespace隔离在各自的命名空间,这个网络栈包括:
- 网卡(Network Interface)
- 回环设备(Loopback Device)
- 路由表(Routing Table)
- iptables规则
-net=host意味着什么?
不开启 Network Namespace,容器使用宿主机的网络栈。容器间会发生端口冲突,像端口资源就需要提前规划。
同主机容器间网络通信?
路由规则 +
Veth Pair设备 + 宿主机网桥
Veth Pair: 两张虚拟网卡(Veth Peer),向其中一个网卡发出的数据包,会直接出现在另一个网卡,不受Network Namespace的影响。
网桥:二层设备,根据MAC地址,将数据包转发到网桥的不同端口上。
- 容器根据
路由表找到出口网卡。 - 数据经过
VethPair,VethPair另一端在宿主机上,名称像veth9c02e56,其又插在docker0网桥上(brctl show命令可查看) 网桥docker0负责二层转发(根据mac地址找到对应端口,此处端口==插在docker0上的虚拟网卡)
类型: | VethPair(网线) | 网桥 | VethPair(网线) |
包流向: eth0 ——– veth9c02aaa > docker0(网桥)> veth9c02bbb ——> eth0
环境 : 容器A |——-| 宿主机 |——| 容器B
举例说明:
源容器A, 目标容器B(172.17.0.3)
- 根据路由规则,确定出口网卡
路由规则
| |
根据目标IP匹配上面的路由规则,这条路由规则的网关(Gateway)是 0.0.0.0,这就意味着这是一条直连规则,即:凡是匹配到这条规则的 IP
包,应该经过本机的 eth0 网卡,通过二层网络直接发往目的主机。
此时需要知道容器B的IP对应的MAC地址(容器A向eth0网卡发arp广播,查找MAC地址)
ARP(Address Resolution Protocol),是通过三层的 IP 地址找到对应的二层 MAC 地址的协议。
向出口网卡发arp请求,获取目标MAC
虚拟网卡“插”在网桥上,会被剥夺处理数据包的能力,降级为网桥上的port,数据包的处理全部由网桥负责。收到arp请求后,docker0会作为二层交换机,将arp转发到其他端口(其他容器虚拟网卡),容器B的虚拟网卡收到请求后,会将自己的MAC回复给容器A。数据包(目的MAC),从源容器eth0网卡发出
源容器A将数据包发出,数据包头包含mac地址,通过Veth-Pair设备到达宿主机vethxxx网卡上,vethxxx网卡作为docker0的从设备,处理数据包的能力被剥夺,数据包直接流入docker0docker0网桥转发至端口(虚拟网卡)
docker0承担二层交换的角色,根据目标mac,在docker0持有的CAM表中查找对应的端口(虚拟网卡),并将数据包转发至此端口
CAM表: 即交换机通过 MAC 地址学习维护的端口和 MAC 地址的对应表
- 根据veth-pair,宿主机流入目标容器。
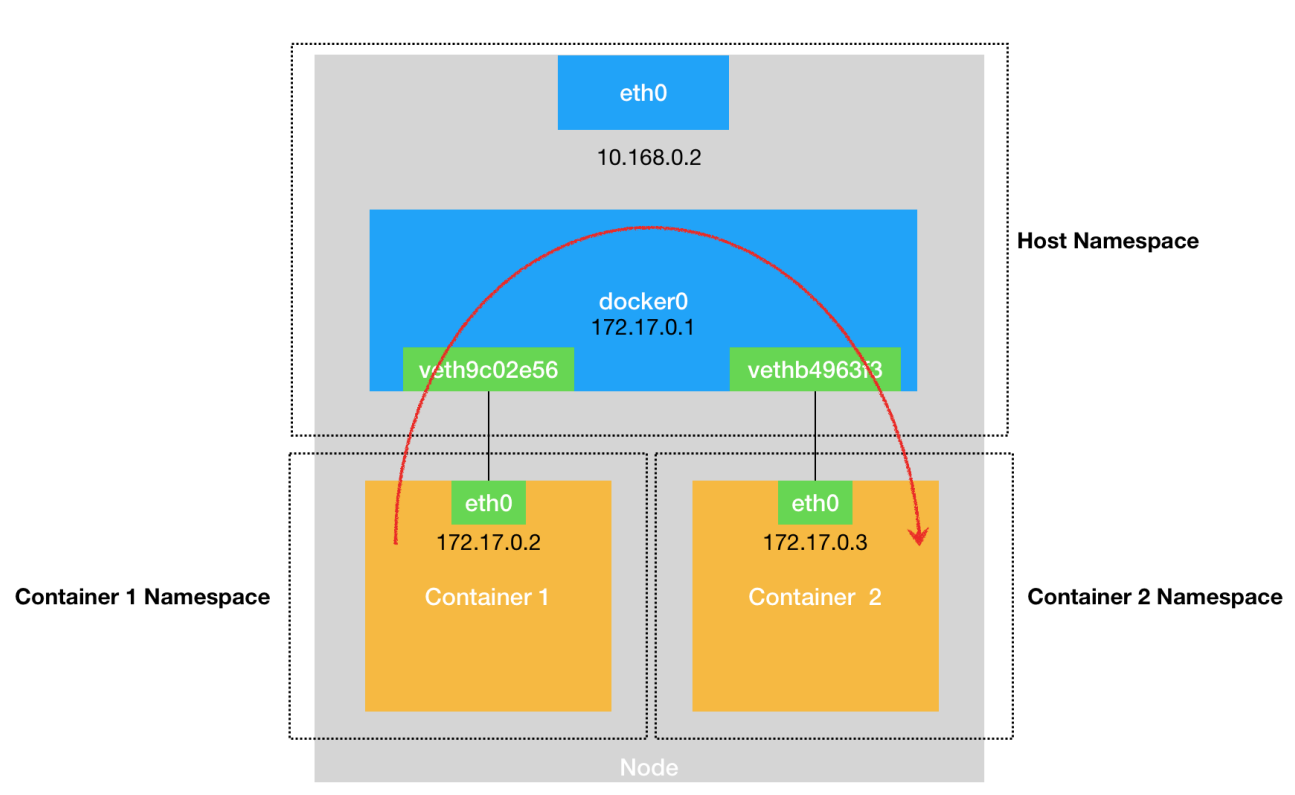
主机访问当前主机上的容器
路由规则(指向docker0) + 网桥docker0 + Veth Pair设备
容器网络能做到哪些,又存在什么问题?
容器网络可以实现:
- 容器访问宿主机网络
- 同一主机,容器之间通信
问题:
就是跨主通信问题
- 源=主机访问跨主容器。
- 源=容器访问跨主容器。
导致以上现象的原因:
- 容器地址重复(每个主机的容器网络都是172.17.0。0/16)
Flannel:中心化容器地址分配, 地址分配表存储在Etcd
- 容器地址不可达(不同主机不知道IP容器网段的地址分配,数据包发到宿主机网络会因为无法路由被丢掉)
解决容器网络可达问题的方案有哪两种?
解决容器网络方案两方面:
- 容器网络IP唯一;
- 容器网络路由可达;
IP地址唯一方面:
中心化网络地址分配
网络路由可达有两种方式:
Overlay方式:相当于软件方式,通过每个主机上的agent实现了一个虚拟网桥
- Flannel: Overlay网络(对应udp/vxlan/IPIP模式),源主机上的
flanneld在数据包添加额外包头封装(主机IP),宿主机网络根据额外包头路由到目标主机,再由目标机器上的flanneld解包。
- Flannel: Overlay网络(对应udp/vxlan/IPIP模式),源主机上的
主机路由方式:通过将容器网络路由表维护到宿主机网络,实现路由可达。
- Calico: 路由方式在underlay网络实现,BGP
- Flannel: hostGW
讲一下Overlay方案的数据包流转
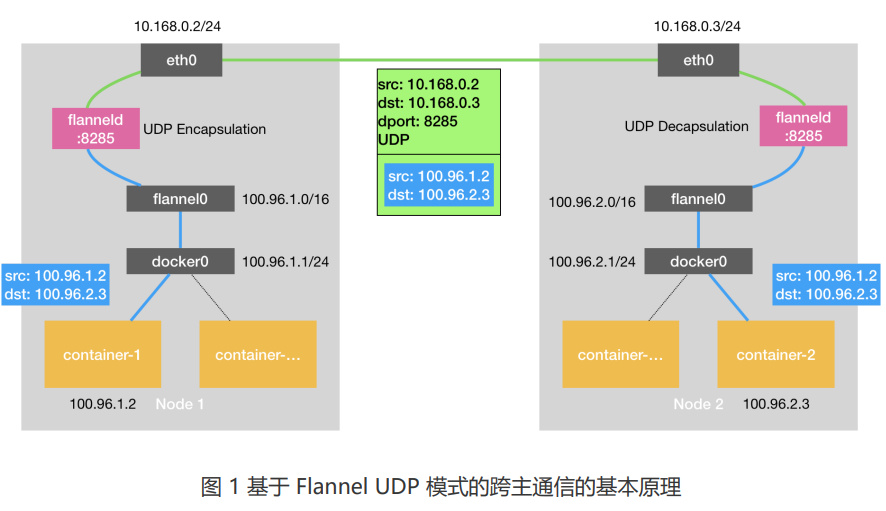
以Flannel-UDP举例
容器A – veth-pair – cni0网桥 – 主机A
路由规则:如果目标IP属于当前主机容器ip段,是直连规则;否则根据宿主机规则进行路由
主机A – 路由规则 – flannel0(TUN设备) – Flannel进程
TUN是一个三层设备,在os内核,传递给用户进程(内核态 – 用户态)
主机A-Flannel进程 – 查子网-主机对应关系(Etcd) – 主机B-Flannel(目的主机IP:8285)
根据目标IP – 匹配对应的目标子网 – 再从Etcd中找到对应主机IP;源flannel对包头封装后,以UDP包的形式发给目标主机
VxLAN\UDP\calico-IPIP对包头处理后,发的都是UDP数据包
主机B-Flannel进程 – flannel0(TUN设备) – 路由规则 – 主机B
flanneld 会直接把这个 IP 包发送给它所管理的 flannel0 设备。用户态 -> 内核态的过程,进入内核态后 Linux 内核网络栈就会负责处理这个 IP 包,就是通过本机的路由表来寻找这个 IP 包的下一步流向。
主机B – cni0网桥 – veth-pair – 容器B
docker0网桥扮演二层交换机的角色,将数据包发送给正确的端口(虚拟网卡),进而通过 Veth Pair 设备进入到目标容器的 Network Namespace 里。
Flannel-Vxlan
- 将tun设备(flannel0)+flanneld进程的组合变成了VTEP(flannel.1)
VTEP: 虚拟隧道端点(VxLAN Tunnel End Point),在内核对二层数据帧进行封装和解包。VTEP设备即有IP,也有MAC。
- 每个主机多条路由规则(由flanneld创建),目标IP==目标VTEP设备的IP,经过flannel.1发出,网关地址为目标VTEP设备的IP
flannel-UDP模式的包头格式?
flannel自定义的包头协议
Host-MAC | Host-IP | UDP | Real-IP | Data
flannel-VxLAN模式的包头格式?
VxLAN是使用UDP封装技术来实现虚拟网络,但一定一定不是UDP模式。
Host-MAC | Host-IP | UDP | vxlan | |Real-MAC | Real-IP | Data
Flannel-hostGW模式怎样实现的?
host-GW 不是Overlay网络,采用的是 主机路由 的方案。就是一个大二层网络,flannel将划分的路由信息刷到主机的路由表,这样每个host上都有整个容器网络的路由数据。
原理:将每个 Flannel 子网(Flannel Subnet,比如:10.244.1.0/24)的“下一跳”,设置成该子网对应的宿主机的 IP地址。
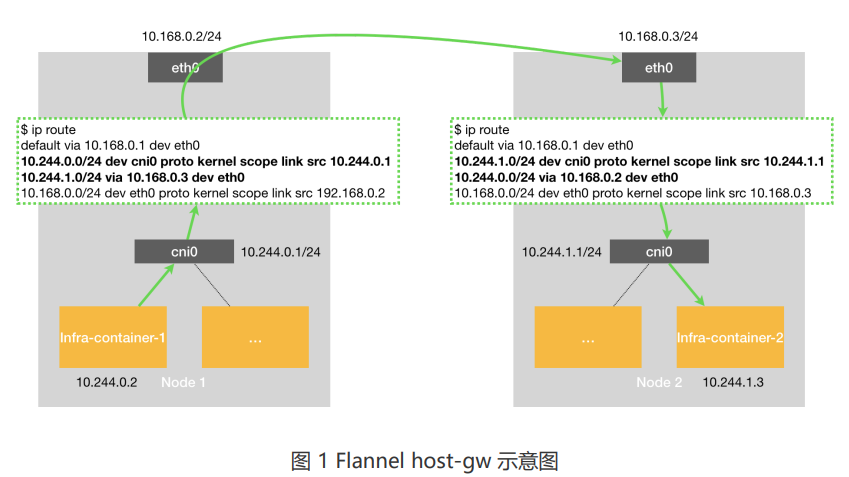
优点: 性能 == 虚拟机直接通信(没有引入额外的封/解包操作)
缺点:1. 必须二层可达(即,所有主机需要在一个路由设备下。因为flannel只能做到修改主机上的路由表,如果主机中间间隔了三次路由设备,数据包从源路由器出,到下一跳路由器时,由于没有下一跳至目标路由器的路由,则会在源路由器处丢掉)
2. 规模小(二层网络节点太多,会存在arp广播风暴问题,因此规模会受限制。)
flannel-UDP模式的优缺点?
优点:简单,直接,易理解
缺点:性能差。数据包头封包/解包在用户态进行,因此数据发送,需要经历两次用户态到内核态的转换(内核态封装,用户态包头解包/封包,内核态发送)。
Flannel-UDP模式发包时,有哪三次内核态、用户态的切换?
第一次:容器进程的数据包,经过docker0网桥进入内核态
第二次:数据包根据路由表、tun设备,进入用户态
第三次:udp封包后,再由tun设备进入内核态,由宿主机网卡发出
flannel-VxLAN模式的优缺点?
优点:速度快
缺点:兼容性问题。
都是UDP封包实现Overlay网络,flannel-VxLAN模式为什么就比UDP模式快?
VxLAN封包技术是Linux内核的标准协议,虽然封包结构更复杂,但因为数据封/解包的过程在内核中完成,避免了内核态、用户态的切换。
calico有哪些模式?
VxLAN模式:overlay方式。VxLAN封包技术,内核支持,速度快但兼容性差。
IPinIP模式:Overlay方式。IPIP封包技术,包头更小、内置在内核,使它性能更好、但安全性更差。
BGP模式:主机路由方式。将修改主机路由表的操作,变为BGP协议。每个节点模拟一个路由器,容器网络的路由喜喜会被广播到其他网络的路由设备。
什么是Underlay,什么是overlay?
Overlay底层依赖Underlay网络,Overlay是依托Underlay中的物理实体,软件虚拟的层级。
延展网络(Overlay Network): 指构建在另一个网络(Underlay)上的计算机网络(虚拟),一种网络虚拟化技术的形式。
Underlay:
为什么集群要有overlay网络?
因为要解决跨主机容器网络不通的问题,除Overlay方案外,还存在主机路由方案(flannel-hostGW/calico-BGP)
什么是VxLAN?
VxLAN: Virtual Extensible LAN(虚拟局域网扩展技术)
VxLAN组建的Overlay网络什么样?
通过UDP封包技术,在真实数据包的包头怎加封装|HOST-MAC|HOST-IP|UDP|VXLAN
TCP、UDP的区别
TCP 面向连接,三次握手四次挥手
UDP 面向报文,不必关心接收端状态
TCP、UDP的联系
两者都是四层协议,都是面向端口的。因此报文结构头中,都有源端口和目的端口。
传输数据过程中: 二层基于mac地址,三层基于IP地址的路由以及根据四层端口找到相应服务的过程都是相同的。
因此VXLAN是封装的UDP包,是因为其主要目的是在现有的IP基础设施上构建一个虚拟的二层网络,以实现跨物理网络的通信。主要关注的也只是封装后的数据包从一个网络节点快速传输到另一个节点。而且overlay是对原始以太网帧进行封装,到达目标节点后,会解封装并恢复成原始的以太网帧,在这个过程中,vxlan不需要关心可靠性,可靠性由上层协议TCP、UDP来保证。
K8S网络演进历史
| 石器时代 | ||||||||
|---|---|---|---|---|---|---|---|---|
| V1.1以前 | v1.1 | v1.2 | v1.3以后 | |||||
| 没有标准,只有假设 | 只有标准,没有实现 | 内置实现,多种扩展 | 关注网络安全、策略 |
- v1.1以前
基本假设:每个pod一个IP,所有pod、主机在一个可以直连直通的扁平网络。
可以理解为:k8s不提供网络的实现,而是提出的部署前置要求。开源第三方方案(calico/weave/flannel等)
- v1.1
出现了CNI标准,但没有具体实现
K8S采用CNI,而非docker出的网络标准CNM,因为CNI更开放,不强依赖docker
一个配置文件
一个可执行文件 (创建/销毁容器时,创建/销毁网络配置时调用)
读取6个环境变量
接受1个命令行参数 (执行的操作、目标网络NameSpec、容器网卡等)
实现两个操作(ADD/DEL) (创建网络的ADD操作/删除网络的DEL操作)
CNI各种插件不同模式的性能对比
Bare > Flannel(host-gw) ~ Calico(bgp) > Calico(ipip) ~ Flannel(vxlan) > Flannel(udp)