一、简述你知道的几种CNI网络插件,并详述其工作原理。K8s常用的CNI网络插件 (calico && flannel),简述一下它们的工作原理和区别。
路由不可达问题:
- Flannel
- Overlay:
- UDP(IP in UDP:
[H-Mac|H-IP|UDP]) - VxLAN(L2 in UDP:
[H-Mac|H-IP|UDP|VxLAN]) - IPIP(IP in IP:
[H-Mac|H-IP])
- UDP(IP in UDP:
- 路由:
- host-GW(Flanneld将容器网络的路由信息写入主机的路由表,每个主机都有完整的容器网络路由信息)
- Overlay:
- Calico
- Overlay
- IPIP
- VxLAN
- 路由
- BGP(Brid:bgp客户端+路由反射器,分发路由+优化大量链接)
- Overlay
- cilium
- ebpf(eBPF 是一种可以在不改变 Kernel 的前提下,开发 Kernel 相关能力的一种技术,)通过在 Linux 内核动态插入强大的安全性、可见性和网络控制逻辑,提供网络互通,服务负载均衡,安全和可观测性等解决方案
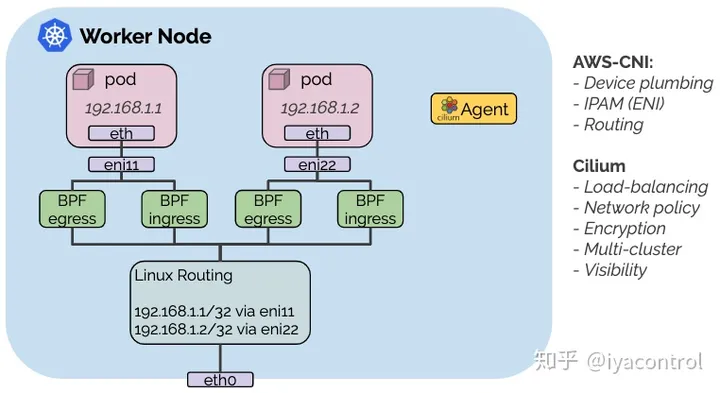
容器内IP地址唯一问题:
Flannel通过中心化容器地址分配解决,使用ETCD存储节点与网段之间关系,节点内部通过Flannel配置docker网络。
二、Worker节点宕机,简述Pods驱逐流程。
检测节点失联(Node Failure Detection):Kubernetes Master 会定期检查节点的健康状态,如果某个节点失联,即不再响应,Master 将意识到该节点可能已经宕机。
Pod 驱逐策略(Eviction Policy):Kubernetes 中的每个节点都会运行一些系统的容器和用户创建的 Pod。在节点失联时,Kubernetes 需要决定如何处理这些 Pod。通常情况下,会按照一定的优先级和策略进行驱逐。
优先级驱逐(Priority-based Eviction):首先会根据 Pod 的优先级来决定是否需要驱逐。优先级较低的 Pod 会被优先驱逐,以保证高优先级的 Pod 尽可能不受影响。
节点驱逐(Node Eviction):在确定要驱逐的 Pod 后,Kubernetes 会尝试将它们迁移到集群中的其他节点上。如果没有足够的资源(如 CPU、内存)可用,或者没有其他节点能够接纳这些 Pod,那么这些 Pod 可能会进入 Pending 状态,直到有资源可用或者重新调度。
Pod 重调度(Pod Rescheduling):如果 Pod 无法重新调度到其他节点上,Kubernetes 可能会启动相应的重调度机制,例如使用调度器来重新安排 Pod 到其他可用节点上。
三、简述你知道的K8s中几种Controller控制器,并详述其工作原理。简述 ingress-controller 的工作机制
k8s 中的controller都遵循通用编排模式:控制循环(control loop)期望状态=yaml 实际状态=k8s
node_lifecycle_controller.go: 节点生命周期控制器。与每一个节点上的 kubelet 进行通信,以收集各个节点以及节点上容器的相关状态信息。 当超出一定时间后不能与 kubelet 通信,那么就会标记该节点为 Unknown 状态。并且节点生命周期控制器会自动创建代表状况的污点,用于防止调度器调度 pod 到该节点。
四、简述k8s的调度机制
- 原理
请求以及调度的步骤:
节点预先、节点优先级排序、节点择优
Kubernetes调度是将Pod分配给节点的过程。
默认情况下,有一个负责调度的Kubernetes实体,称为kube-scheduler,它将在控制平面上运行。Pod将在Pending状态下开始,直到找到一个匹配的节点。
将一个Pod分配给一个节点的过程遵循这个顺序。
预选: 在预选过程中,kube-scheduler将选择当前Pod可能被放置的所有节点。这里将考虑到污点和容忍度等特征。一旦完成,它将有一个适合该Pod的节点列表。
打分: 在打分过程中,kube-scheduler将从上一步得到的列表中,给每个节点分配一个分数。这样一来,候选节点就会从最合适到最不合适排序。如果两个节点有相同的分数,kube-scheduler会将它们随机排序。
如果没有合适的节点让Pod运行,Kubernetes将启动抢占程序(试图驱逐低优先级
Priority Class的Pod,以便分配新的Pod)。
五、简述kube-proxy的三种工作模式和原理
KubeProxy是运行在每个worker节点的网络代理组件,使发往service的流量负载均衡到相应的POD
监听资源:
- service
- endpoint
- endpointSlices:(启用 EndpointSlice)
- node(启用服务拓扑)
四种代理模式方式:
- user_space(k8s-v1.2被淘汰)
- iptables(k8s-v1.2后的默认模式)
- ipvs
- kernel_space(专用windows,userspace的早期实现。略)
userspace详述
实现方式:
kube-proxy监听端口,所有访问svc的请求都转发至此端口,然后在proxy内进行转发。每多一个svc,多一个监听端口+一个iptables规则
数据流向:
访问服务的ClusterIP -> 根据iptables转发到kube-proxy -> kube-proxy查找注册中心,将请求发送给实例
负载均衡算法:轮询
优点:当某个实例请求失败,可再重试其他实例
缺点:效率低,因为第二步涉及内核态到用户态的切换
iptables实现详述
kube-proxy将规则添加到NAT-PreRouting钩子上,以实现其NAT和负载均衡功能。
负载均衡策略:随机选择后端(随机数),第一个Pod没有响应,则连接失败
缺点:
- iptables更新是全量更新。(service较多时,创建、更新服务会引入时延)
- iptables的查询为数组遍历。(查询性能增加是线性增长的)
- 负载均衡算法只支持随机等成本分发。
综上,1k-svc(1W-pod)以上规模时,建议选择ipvs
ipvs实现详述
ipvs是Linux内核专用于负载均衡的组件。ipvs基于hash表实现,iptables基于数组。ipvs连接处理性能恒定,不受集群规模影响。
负载均衡策略:
- rr: round-robin(轮询)
- lc: least connection (最小开放连接数)
- dh: destination hashing(目标散列)
- sh: source hashing(源地址散列)
- sed: shortest expected delay()
- nq: never queue()
缺点:IPVS与iptables的数据包路径不同,如果有IPVS与其他使用iptables的程序一起使用需求,需要考虑兼容性。
发展趋势
- 接口化,类似CNI(nftables作为kube-proxy后端的pr至今未被合并)
- 去kube-proxy, 由容器网络框架实现(cilium)
在集群中不超过1000个服务的时候,iptables 和 ipvs 并无太大的差异。而且由于iptables 与网络策略实现的良好兼容性,iptables 是个非常好的选择。
当你的集群服务超过1000个时,而且服务之间链接大多没有开启keepalive,IPVS模式可能是一个不错的选择。
六、k8s每个Pod中有一个特殊的Pause容器,能否去除,简述原因
k8s类比linux进程组,提出了pod概念,即容器组。用来处理需要部署同一环境,密切协作的一组容器的场景。pause就是那个init容器,起到创建环境,维护环境的职能。
作用:
- 维持pod内非infra容器的关系对等,可不须考虑先后。
- NetNamespace隔离:pause负责创建并维护NetNS,其他容器共享此网络命名空间。
- 维护Pod生命周期(进程隔离):确保其他容器停止时,Pause容器仍运行,以维护Pod生命周期。
- 资源隔离
- IP地址维护:Pod_IP与Pod的生命周期保持一致
- 生命周期管理
pod创建过程
七、简述pod中Readiness和Liveness的区别和各自应用场景
Liveness: 存活性检测,影响K8S重启pod进行自愈的过程。 running
Readiness: 服务可用性检测,会影响pod状态,为ready
TCP(可建立连接)|HTTP(状态码2xx,3xx)|命令(退出码=0)
八、Pod启动失败如何解决以及常见的原因有哪些
九、简述K8s中label的几种应用场景
10.简述你知道的Jenkins Pipeline中脚本语法中的几个关键字
11、Docker 的网络通信模式。
12、K8s有哪些重要组件,简述一下集群部署的流程。
13、你所用的到的日志分析工具有哪些以及它们如何与K8s集群通讯。
14、Kubelet 与 kubeproxy 作用。Kubeproxy 的三种代理模式和各自的原理以及它们的区别。
15、Iptables 四个表五个链
Pod相关配置
Projected Volume(投射数据卷): 为容器提供预先定义好的数据的Volume,从容器的角度,信息仿佛是被Kubernetes“投射”(Project)进入容器当中.
- secret
- ConfigMap
- Downward API: (pod labels信息)
- ServiceAccount Token
PodPreSet: 对 Pod 进行批量化、自动化修改的工具对象.
描述Informer机制
概括:Informer就是拥有本地缓存和索引机制,可以注册EventHandler的client
详述:Informer通过ListAndWatch机制,把ApiServer的事件缓存到了本地,并更新、维护这个缓存(首先获取全量,再watch变量);之后根据事件触发EventHandler。
除了上面实时的更新,还存在resync机制,会根据最近一次List的结果强制刷新一次,保证缓存的有效性。(注意这个操作的资源ResourceVersion)kubernetes-operator异常退出,如何保证add\del等操作的幂等性。
API-Server处理资源创建的流程
- 接受Post请求,对请求进行过滤,完成一些前置操作(授权、超时处理、审计);
- MUX和Routes流程,找到相应资源的handler(match-Group -> match-version -> match -> resource)
- 重要:根据资源定义,创建资源对象。
3.1. 泛化:convert(根据Post的参数转换为SuperVersion,包含此资源定义的所有字段,类似泛化);
3.2. Admission(admission+initializer) + Validation(被验证过的API对象,保存再Registry的struct中,如果能从Registry查询到,即验证通过) - 持久化:将Post提交版本的资源定义,序列化并存储至ETCD。
自己写一个Controller要做哪几步
- pkg/apis/samplecrd下创建register.go文件,放置全局变量,doc.go文件,文档源文件(
// +k8s:deepcopy-gen=package:为整个v1包的所有类型定义生成DeepCopy方法,而+groupName=samplecrd.k8s.io:定义包名)
- pkg/apis/samplecrd下创建register.go文件,放置全局变量,doc.go文件,文档源文件(
k8s都有哪些地方进行了插件化
- 编排领域:controller CRD
- 调度:scheduler
- 容器运行时:CRI
- 存储:CSI
- 网络:CNI
感觉K8S有价值的功能增加
- kube-proxy增加插件机制实现
- kubelet关于cgroups的限制,增加磁盘IO以及网络IO、GPU、NPU的限制。