系列导航
本系列从 Pod 网络连通入手,逐步展开到 K8s 网络全景。
① 概念 → ② Flannel → ③ Calico → ④ 流量路径 → ⑤ Cilium → ⑥ 对比 → ⑦ 排障 ‖ ⑧ 开发 → ⑨ 多网卡 → ⑩ AI 演进
| 顺序 | 文章 | 定位 |
|---|---|---|
| ① | 概念与入门 | 基础——主机网络、Docker 网络、CNI 标准、方案分类树 |
| ② | Flannel 详解 | CNI 实现——Overlay 封装(UDP/VXLAN/HostGW)与抓包 |
| ③ | 本篇 - Calico 详解 | CNI 实现——三层路由(BGP/IPIP)+ NetworkPolicy |
| ④ | 流量路径全解析 | 全貌——Pod/Service/Ingress/Egress,揭示 CNI 的边界 |
| ⑤ | Cilium 详解 | 超越 CNI——eBPF 统一 Pod + Service + L7 + Hubble |
| ⑥ | 插件对比与选型 | 选型——5 插件横向对比 + 决策树 |
| ⑦ | 排障思路与常用命令 | 运维——工具链 + 场景排查 + 性能 |
| — | 核心路径 ↑ | 扩展展望 ↓ |
| ⑧ | CNI 插件开发指南 | 扩展——基于 CNI 规范开发自定义插件 |
| ⑨ | 多网卡方案详解 | 进阶——Multus + SR-IOV/ipvlan 多网口实战 |
| ⑩ | AI 时代网络演进 | 展望——GPU 网络、eBPF 加速、未来方向 |
Calico 由 Tigera 维护,核心设计思想:将二三层流量全部收敛为三层路由——不存在类似 Flannel cni0 的独立网桥,veth pair 对端直接挂在宿主机协议栈,所有流量走三层路由决策。
1. Calico 架构
组件
Felix —— 每个节点上的核心 Agent,以 DaemonSet 部署。负责本节点路由表、iptables 规则、网络策略的配置与同步。
BIRD —— BGP 客户端,负责向集群内/外宣告本节点的 Pod 子网路由,动态扩散路由信息。
confd —— 监听 Etcd/K8S API 变更,触发 BIRD 和 Felix 重载配置。
Pod-Node 通信模型
Calico 通过两个关键机制将 Pod 流量全部转换为三层路由:
1. 虚拟网关 169.254.1.1 —— 每个 Pod 的默认路由都指向 169.254.1.1,但没有任一网卡对应此 IP。Calico 在宿主机 cali* 网卡上开启代理 ARP,当 Pod 发 ARP 找 169.254.1.1 的 MAC 时,宿主机用自己的 MAC(ee:ee:ee:ee:ee:ee)应答。Pod 所有出站流量因此被引向宿主机协议栈。
2. 代理 ARP —— ARP 广播被抑制在宿主机内,不会泛洪到其他节点,避免了广播风暴和 ARP 表膨胀。/proc/sys/net/ipv4/conf/cali*/proxy_arp = 1
- 选取节点
node1中的容器pod-a作为实验节点,进入容器pod-a查看IP地址:
172.17.8.2/32容器IP地址为/32位的地址,表示容器是一个单点的局域网
| |
- 查看容器
pod-a的默认路由:
根据以下路由表信息可以知道:
169.254.1.1为容器默认网关,但没有任一网卡对应此IP地址。
当一个数据包的目的地址不是本机时,会查询路由表,从路由表查询到网关后,会通过arp获取网关的mac地址,然后在二层网络数据包中将目标mac替换为网关的mac地址。也就是说,网关IP只是为了能找到网关的mac地址,响应arp就行。
| |
- 查看容器的arp缓存:
ip neigh: 用于查看系统上的邻居表(Neighbor Table),通常也称为ARP缓存表。这个表存储本机与其它机器或网络设备之间的关联。
返回信息依次为: 目标设备IP地址(169.254.1.1) 与目标设备通信的网卡(dev eth0) 目标设备mac地址(lladdr ee:ee:ee:ee:ee:ee) 与目标设备通信状态(REACHABLE)
arp获取mac地址过程:内核会对外发送arp请求,询问二层网络中拥有169.254.1.1地址的mac,拥有此ip的设备会在二层网络中响应自己的mac地址。
mac地址为calico设置的,如何响应arp:容器和主机都没有169.254.1.1IP地址,甚至连主机上的端口 calicba2f87f6bb,MAC 地址也是一个无用的 ee:ee:ee:ee:ee:ee。按道理容器和主机网络根本就无法通信,但calico采用了网卡代理arp功能。
| |
- 代理arp
代理ARP(Proxy ARP): 是 ARP 协议的一个变种,当 ARP 请求目标跨网段时,网关设备收到此 ARP 请求,会用自己的 MAC 地址返回给请求者。
确认宿主机开启了代理arp:
| |
与 Flannel VXLAN 的关键区别
| 对比点 | Flannel VXLAN | Calico VXLAN |
|---|---|---|
| veth 对端 | 插入 cni0 网桥,降级为端口 | 直接挂在宿主机 cali* 接口 |
| 同节点 Pod 通信 | cni0 CAM 二层转发 | 宿主机路由表直接三层转发 |
| 跨节点路径 | Pod → cni0 CAM → 路由 → VTEP | Pod → 路由 → VTEP(无网桥层) |
| 广播/ARP | 依赖 cni0 泛洪 | 代理 ARP 抑制在主机内 |
2. Calico 后端模式
Calico 支持四种后端,按数据路径分为:Overlay 封装(VXLAN/IPIP)、路由模式(BGP/RR)。
| backend | 适用场景 | 优点 | 限制 | 层次 | 实现方式 |
|---|---|---|---|---|---|
| VxLAN | 底层不支持 BGP,需二层 Overlay | 兼容性好,通用标准协议 | 有封装开销(~50B) | L2 Overlay | 内核态 VXLAN,控制平面与 BGP 解耦 |
| IPIP | 底层不支持 BGP,只需三层互通 | 封装开销极小(~4B),性能好 | 只支持 IP 单播 | L3 Overlay | tunl0 设备内核态 IP-in-IP |
| BGP | 底层网络支持 BGP,追求最高性能 | 性能最高,可观测性好 | 要求底层网络支持 BGP | 路由(不封装) | BIRD 通过 BGP 扩散 Pod 子网路由 |
| RR | BGP 大规模部署(>50 节点) | 避免全节点 Mesh 的 N² 复杂度 | 需额外配置 RR 节点 | 路由 | BGP Route Reflector |
2.1 Overlay: VXLAN 模式
cni0 网桥,直接对接宿主机 cali* 接口进入 VTEP 隧道,路径比 Flannel 少一跳 CAM 转发。2.1.1 组件概念
Calico VXLAN 模式与 Flannel VXLAN 封装协议相同,区别在数据路径——去掉了网桥层:
| 对比项 | Flannel VXLAN | Calico VXLAN |
|---|---|---|
| veth 对端 | 插入 cni0 网桥,降级为端口 | 直接挂在宿主机 cali* 接口 |
| 同节点 Pod 通信 | cni0 CAM 二层转发 | 宿主机路由表直接三层转发 |
| 跨节点路径 | Pod → cni0 CAM → 路由 → VTEP | Pod → 路由 → VTEP(无网桥层) |
2.1.2 路由规则对比
Flannel 的 veth 插入 cni0 网桥后降级为端口,失去独立三层转发能力。本地 Pod 流量共享一条路由:
| |
Calico 的 cali* 没有网桥承载,每个 Pod 的 veth 对端保留完整网卡能力,不降级。代价是每个 Pod 需要一条独立路由:
| |
假设节点上有 30 个 Pod——Flannel 一条路由,Calico 三十条。原理如下:
Flannel VXLAN:
Pod eth0 ←→ veth pair → cni0端口(已降级)
↓
IP包进入cni0后,cni0作为二层网桥按CAM转发到目标端口
同节点:乙Pod.MAC → CAM查端口 → 乙veth → 乙Pod
跨节点:宿主机路由 10.244.2.0/24 → flannel.1 → VXLAN封装
Calico VXLAN:
Pod eth0 ←→ veth pair → cali0a4fde325ea (独立网卡,不降级)
↓
IP包进入cali*接口后直接进宿主机路由决策
同节点:查路由表匹配 /32 → 下一跳 = 乙cali* → 乙Pod
跨节点:查路由表匹配远端子网 → vxlan.calico → VXLAN封装结论: Calico 用更多路由规则换取更精简的数据路径——去掉了网桥层的 CAM 学习和广播泛洪,代价是路由表规模随 Pod 数量线性增长。
2.2 Overlay: IPIP 模式
通路:tunl0 设备内核态 IP-in-IP 封装——在原始 IP 包外再封一层 IP 头,纯三层隧道,~4B 开销,不涉及 MAC 学习。
封包格式:|HostMAC|HostIP|IPIP|内层IP|Data|
2.2.1 组件概念
IPIP (IP-in-IP) 是 Linux 内核的一种隧道模式,将一个 IP 包封装在另一个 IP 包中。作用相当于一个基于 IP 层的网桥——通过两端路由做一个 tunnel,把不通的网络点对点连接起来。
IPIP vs VXLAN 对比:
| 维度 | IPIP | VXLAN |
|---|---|---|
| 封装开销 | ~4B(仅 IPIP 头) | ~50B(MAC+IP+UDP+VNI) |
| 工作层次 | L3(IP-in-IP) | L2(L2-in-UDP) |
| 二层流量 | 不支持(仅 IP 单播) | 支持(ARP、多播等) |
| MAC 学习 | 不需要 | 需要 FDB 表 |
| 性能 | 略优 | 良好 |
| 适用场景 | 只需三层互通 | 需二层互通或标准 Overlay |
2.2.2 封装流程
流程说明
报文从 Pod 发出,根据路由发往网关 169.254.1.1:
2.2.3 抓包验证
以两个node上的两个容器为例,说一下报文的流动过程。
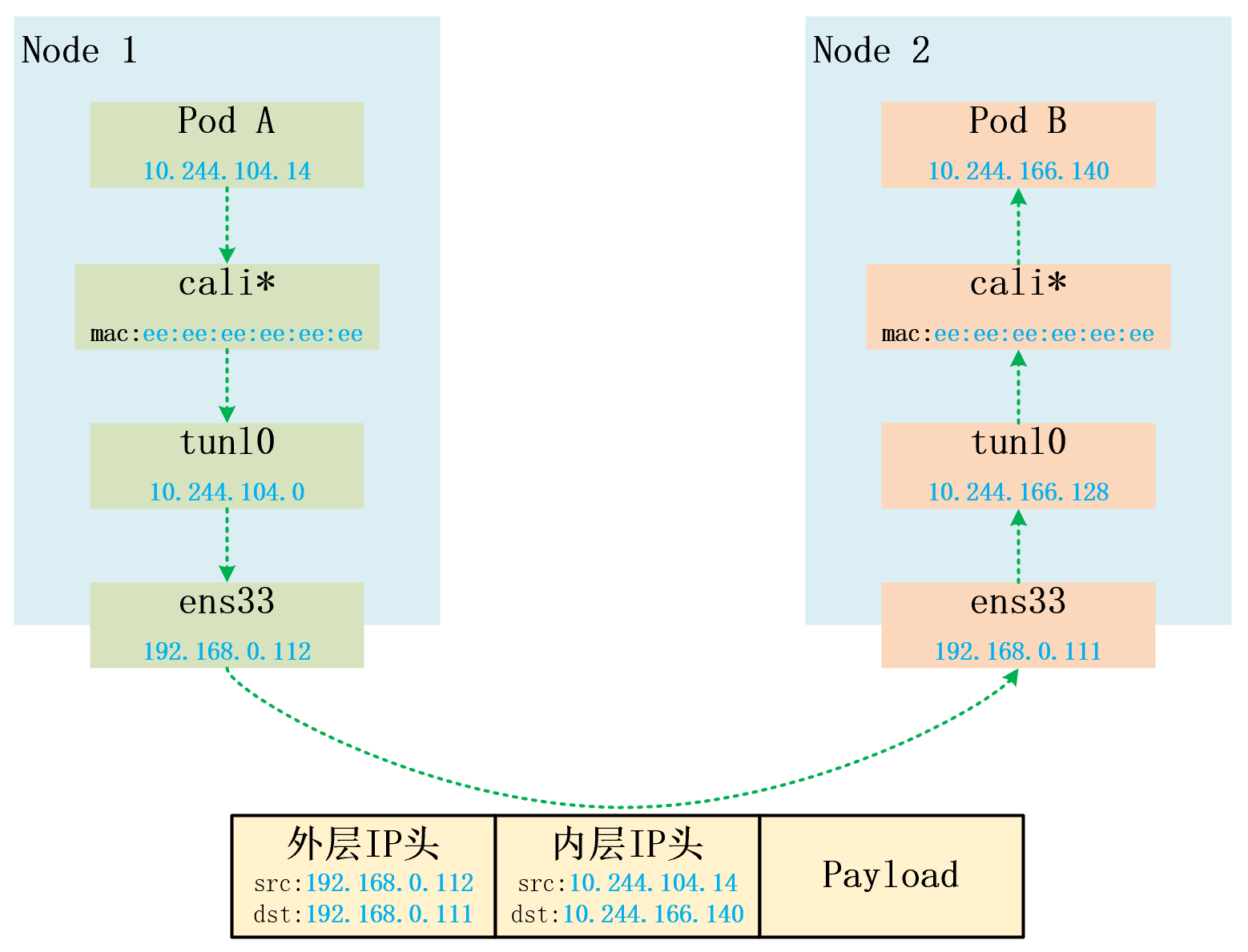
报文从PodA(10.244.104.14)发出,根据路由发往容器中的网关169.254.1.1
但PodA中路由信息如下(没有):
| |
查看网关通向的二层地址(mac地址),容器中网关arp地址为ee:ee:ee:ee:ee:ee:
| |
集群节点上执行下面命令,查看mac地址ee:ee:ee:ee:ee:ee对应的网卡
| |
容器中网卡是veth的pair虚拟网卡,一端连接容器(pod-a:eth0),一端连接宿主机(node-a:cali0a4fde325ea)。因此,执行下面命令,查看容器内网卡编号:
| |
确认宿主机编号为14的网卡
| |
因此容器 pod-a 的报文通过 cali0a4fde325ea 网卡到达宿主机 node1,然后根据宿主机路由发往 tunl0 进入 IPIP 隧道。
2.3 Underlay: BGP 模式
BIRD 向全集群扩散 Pod 子网路由,数据包直接按宿主机路由表转发,零封装。2.3.1 组件概念
Calico BGP 的核心设计: 每个节点都是一个 vRouter,通过 BGP 协议宣告本节点的 Pod 子网路由。
工作原理:
- 每个节点运行
Felix进程,负责本机路由、iptables 规则、网络策略 - 每个节点运行
BIRD(BGP 客户端),负责扩散 Pod 子网路由 - BGP 有三种部署模式:
| 模式 | 适用规模 | 说明 |
|---|---|---|
| Node-to-Node Mesh | < 50 节点 | 全节点两两建立 BGP Peer,配置最简单 |
| Route Reflector | > 50 节点 | 指定中心路由反射器,其他节点只与反射器建 Peer |
| External BGP | 机房级 | 与物理机房路由器建立 BGP Peer,Pod 子网直接宣告到机房网络 |
2.3.2 主要流程
数据包流程: Pod → 宿主机路由表 → 目标节点 → 目标 Pod
核心优势:
- 性能最高,可观测性最好(标准网络工具
tcpdump、traceroute都能调试) - 原生支持 NetworkPolicy(iptables/eBPF 实现)
- 可与物理网络的 BGP 路由器对等,直接将 Pod 路由宣告到机房网络
限制:机房网络必须允许 BGP 协议(很多公有云 VPC 不支持),部署复杂度高于 Flannel。
2.4 Underlay: Route Reflector 模式
2.4.1 组件概念
Calico维护的网络在默认是(Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。
但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
3. 流量加密
集群内的 pod 流量使用 Wireguard 进行加密,它可以创建和管理节点之间的隧道,提供安全的通信。
4. 网络策略
Calico 的网络策略实现了拒绝/匹配规则,可通过清单为 pod 分配入口策略。支持全局范围策略,可与 Istio 集成控制 pod 流量。
5. 总结
| 维度 | BGP | IPIP | VXLAN |
|---|---|---|---|
| 封装开销 | 0 | ~4B | ~50B |
| 路由方式 | BGP 动态路由 | IP-in-IP 隧道 | L2-in-UDP 隧道 |
| 性能 | 最高(裸机) | 良好 | 良好 |
| 二层流量 | 不支持 | 不支持 | 支持 |
| 适用场景 | 自建机房 | 公有云(只需L3) | 公有云(需L2) |