Calico由Tigera维护,是k8s中另一个流行的开源CNI插件。适用于网络性能、灵活性和功率等因素至关重要的环境。
与 Flannel 不同,Calico 提供先进的网络管理安全功能,同时提供主机和 pod 之间的网络连接。
1. calico架构
组件:
在标准的 Kubernetes 集群上,Calico 可以作为 DaemonSet 轻松部署在每个节点上。集群中的每个节点都将安装三个 Calico 组件:Felix、BIRD和用于管理多个网络任务的confd。Felix作为 Calico 代理处理节点路由,而BIRD和confd则管理路由配置更改。
原理:
Calico的设计比较新颖,Flannel的Host-Gateway模式之所以不能跨二层网络,是因为它只能修改主机的路由,Calico把改路由表的做法换成了标准的BGP路由协议。
相当于在每个节点上模拟出一个额外的路由器,由于采用的是标准协议,Calico模拟路由器的路由表信息就可以被传播到网络的其他路由设备中,这样就实现了在三层网络上的高速跨节点网络。
不过在现实中的网络并不总是支持BGP路由的(部分内网和公网的局部区域不支持BGP),因此Calico也设计了一种IPIP模式,使用Overlay的方式来传输数据。IPIP的包头非常小,而且也是内置在内核中的,因此它的速度理论上比VxLAN快一点点,但安全性更差。
或 VXLAN 可以实现覆盖网络模式,像覆盖网络一样封装跨子网发送的数据包。
Calico BGP 协议使用未封装的 IP 网络结构,无需用封装层封装数据包,从而提高了k8s工作负载的网络性能。
2. 流量加密
集群内的 pod 流量使用Wireguard进行加密,它可以创建和管理节点之间的隧道,提供安全的通信。
3. Calico后端模式
Flannel的Host-Gateway模式之所以不能跨二层网络,是因为它只能修改主机的路由,Calico把改路由表的做法换成了标准的BGP路由协议。
但带来了新的问题:部分内网和公网的局部区域不支持BGP,因此Calico的妥协机制为IPIP模式,calico也支持vxlan模式
| backend实现方式 | 适用场景 | 优点 | 限制 | 基于哪一层 | 实现方式 |
|---|---|---|---|---|---|
| VxLAN | 普遍适用,官方推荐 | 性能良好,手动干预少(易部署) | 与部分内核不兼容 | 三层网络层 | 使用设备flannel.0进行封包解包,不是内核原生支持,上下文切换较大,性能非常差 |
| IPIP | 测试、在比较老的不支持VXLAN的Linux内核部署 | 简单、兼容性好 | 性能差 | 三层网络层 | 使用flannel.1进行封包解包,内核原生支持 |
| bgp | 网络性能要求比较高的场景 | 网络性能高 | 对基础网络架构有要求 | 二层网络 | 无需flannel.1这样的中间设备,直接宿主机当作子网的下一跳地址,性能最强 |
| RR | 网络性能要求比较高的场景 | 网络性能高 | 对基础网络架构有要求 | 二层网络 | 无需flannel.1这样的中间设备,直接宿主机当作子网的下一跳地址,性能最强 |
3.1 Pod-Node通信的网络模型
Node上每有一个Pod,则会在节点上创建一个
veth pair, Calico 通过一个巧妙的方法将 Pod 的所有流量引导到一个特殊的网关 169.254.1.1,从而引流到主机的 calixxx 网络设备上,最终将二三层流量全部转换成三层流量来转发。
在主机上通过开启代理 ARP 功能来实现 ARP 应答,使得 ARP 广播被抑制在主机上,抑制了广播风暴,也不会有 ARP 表膨胀的问题。
- 选取节点
node1中的容器pod-a作为实验节点,进入容器pod-a查看IP地址:
172.17.8.2/32容器IP地址为/32位的地址,表示容器是一个单点的局域网
| |
- 查看容器
pod-a的默认路由:
根据以下路由表信息可以知道:
169.254.1.1为容器默认网关,但没有任一网卡对应此IP地址。
当一个数据包的目的地址不是本机时,会查询路由表,从路由表查询到网关后,会通过arp获取网关的mac地址,然后在二层网络数据包中将目标mac替换为网关的mac地址。也就是说,网关IP只是为了能找到网关的mac地址,响应arp就行。
| |
- 查看容器的arp缓存:
ip neigh: 用于查看系统上的邻居表(Neighbor Table),通常也称为ARP缓存表。这个表存储本机与其它机器或网络设备之间的关联。
返回信息依次为: 目标设备IP地址(169.254.1.1) 与目标设备通信的网卡(dev eth0) 目标设备mac地址(lladdr ee:ee:ee:ee:ee:ee) 与目标设备通信状态(REACHABLE)
arp获取mac地址过程:内核会对外发送arp请求,询问二层网络中拥有169.254.1.1地址的mac,拥有此ip的设备会在二层网络中响应自己的mac地址。
mac地址为calico设置的,如何响应arp:容器和主机都没有169.254.1.1IP地址,甚至连主机上的端口 calicba2f87f6bb,MAC 地址也是一个无用的 ee:ee:ee:ee:ee:ee。按道理容器和主机网络根本就无法通信,但calico采用了网卡代理arp功能。
| |
- 代理arp
代理ARP(Proxy ARP): 是 ARP 协议的一个变种,当 ARP 请求目标跨网段时,网关设备收到此 ARP 请求,会用自己的 MAC 地址返回给请求者。
确认宿主机开启了代理arp:
| |
3.2 BGP
Flannel host-gw方式的改进版
边界网关协议(Border Gateway Protocol, BGP):是互联网上一个核心的去中心化自治路由协议。BGP不使用传统的内部网关协议(IGP)的指标。
3.3 IPIP
IPIP模式(IP in IP Overlay):即在IP报文基础上,又封装了一个IP头,和VXLAN类似(但封装头更小,比vxlan理论性能稍强)
| HostMac | HostIP | RealIP | Data |
把 IP 层封装到IP层的一个tunnel。作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需IP,
而这个IPIP则是通过两端的路由做一个tunnel,把两个本来不通的网络通过点对点连接起来。
以两个node上的两个容器为例,说一下报文的流动过程。
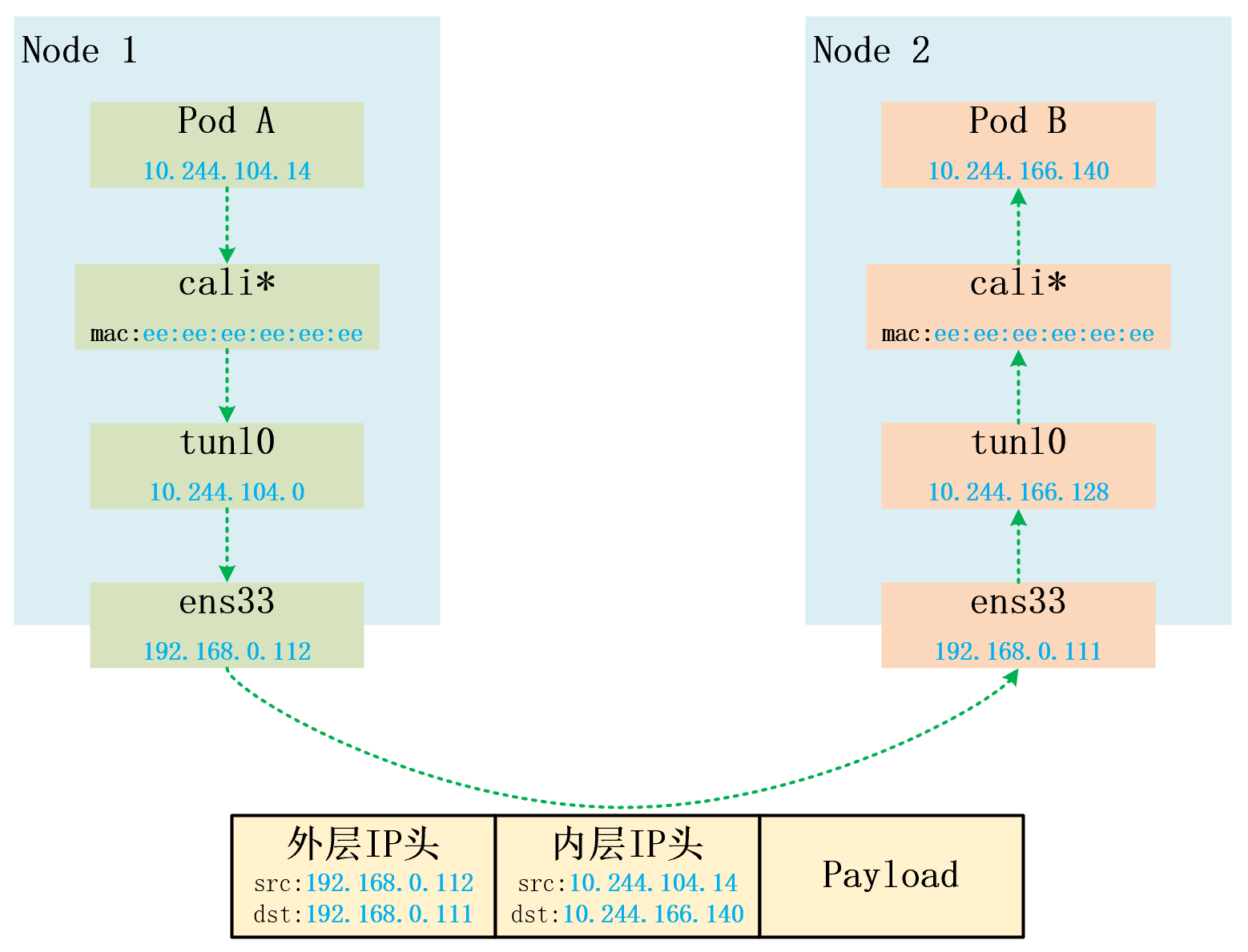
报文从PodA(10.244.104.14)发出,根据路由发往容器中的网关169.254.1.1
但PodA中路由信息如下(没有):
| |
查看网关通向的二层地址(mac地址),容器中网关arp地址为ee:ee:ee:ee:ee:ee:
| |
集群节点上执行下面命令,查看mac地址ee:ee:ee:ee:ee:ee对应的网卡
| |
容器中网卡是veth的pair虚拟网卡,一端连接容器(pod-a:eth0),一端连接宿主机(node-a:cali0a4fde325ea)。因此,执行下面命令,查看容器内网卡编号:
| |
确认宿主机编号为14的网卡
| |
因此容器(pod-a-bc2sm)中的报文通过cali0a4fde325ea网卡到达宿主机(node1)然后根据宿主机路由,将报文发往tunl0
3.4 Route Reflector 模式(RR)(路由反射):
Calico维护的网络在默认是(Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。
但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
4. 网络策略
Calico 的网络策略实现了拒绝/匹配规则,这些规则可通过清单应用,为 pod 分配入口策略。用户可以定义全局范围的策略,并与 Istio 服务网格集成,以控制 pod 流量、提高安全性并管理k8s的工作负载。
5. 实验举例
待整理
6. 总结
calico具有以下的优点:
- 高性能:Calico BGP 协议使用未封装的 IP 网络结构,无需用封装层封装数据包,从而提高了k8s工作负载的网络性能。
- 支持流量加密:集群内pod流量使用
Wireguard创建vpn进行安全的通信。 - 便于跟踪调试:因为不存在操纵数据包的包装器,跟踪和调试比其他工具容易得多。开发人员和管理员可以轻松了解数据包行为,并使用策略管理和访问控制列表等高级网络功能。
- 支持网络策略:
总之,对于希望控制网络组件的用户来说,Calico 是一个极佳的选择。Calico 可以与不同的k8s平台(如 kops、Kubespray)轻松配合使用,也可按需向Calico Enterprise获取商业支持。